Reliability Key Principles
Reliability stands as the initial concept in the RAMS framework, surrounding all aspects of the system. Without considering reliability, safety becomes a precarious notion. Safety issues often arise from a lack of reliability in safety systems or other related concerns that may lead to injuries.
Similarly, maintainability, firstly characterized with the TTR Time To Repair is relevant only when a system encounters breakdowns, as the more it happens, the more the maintenance team will have occupation. Availability, closely tied to reliability, is frequently expressed as a percentage requirement (e.g. “must be in operation 99% of the time”). Availability, in essence, is the ratio of the system’s reliable performance (Operating time) to the total time.
Reliability Main Definitions
The reliability metrics are characterized with one of the following parameters:
- Lambda, the failure rate per hour
- MTBF or “Mean Time Between Failures”, which equals 1/lambda.
But these notions come often with a few others, in duality with maintenance:
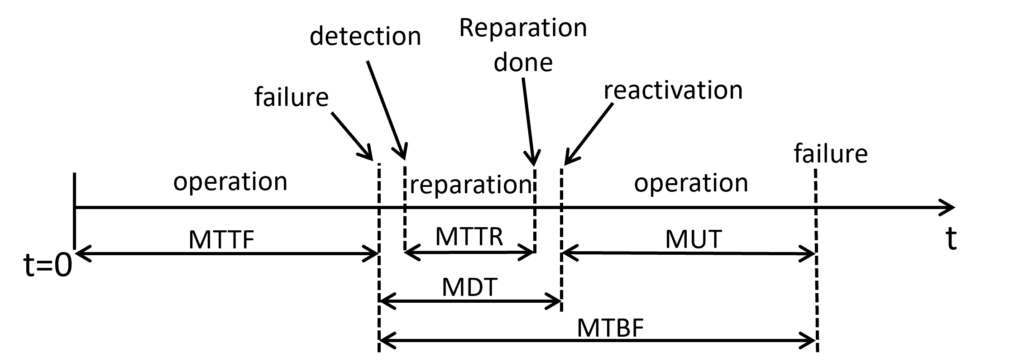
- MTTR – Mean Time To Repair:
- Definition: MTTR represents the average time it takes to repair a failed system or component after a failure has occurred.
- Formula: MTTR = Total Downtime / Number of Failures
- MDT – Mean Downtime:
- Definition: MDT is the average duration that a system or component is unavailable or non-functional due to failures, including both the repair time and any additional time required to bring the system back to full operation.
- Relation to MTTR: MDT is essentially the sum of MTTR and any additional downtime needed to restore the system to its normal operating state.
- MTBF – Mean Time Between Failures:
- Definition: MTBF represents the average time elapsed between consecutive failures of a system or component. It is a measure of the system’s reliability.
- Formula: MTBF = Total Uptime / Number of Failures
- Relation to MTTR: The MTTR is often considered neglectable compared to the MTBF, that’s why the reliability of a system is commonly characterized with the MTBF, although a more accurate reference would be the MUT.
- MUT – Mean Up Time:
- Definition: MUT is the average time that a system or component is operational between failures.
- Formula: MUT = MTBF + MTTR
- Relation to MTBF and MTTR: MUT is the sum of MTBF and MTTR. It represents the average time a system remains operational before the occurrence of a failure and the time it takes to restore functionality after a failure.
- MTTF – Mean Time To Fail:
- Definition: MTTF is the average time that a system or component is operational before its first failure. It is mostly used for disposable systems, rarely otherwise.
How to verify the Reliability of a component or a system?
A few differences exist between components and complex systems to estimate their reliability. A component is a very simple and elementary subsystem: in any case it has few failure rates, and its splitting wouldn’t bring any more simplicity. For example, a relay is considered a component because it has few and simple-to-handle failure modes: untimely continuity or untimely open circuit (in a nutshell), and dismembering all the parts would not allow to reduce even more the list of failure modes. A complex system is an assembly of all its components.
The way we define and verify reliability objectives depends on the type of product we are dealing with.
- Off-the-Shelf Products: For products readily available in the market, reliability is usually a stated value in the product catalog, or stems from a return of experience database.
- Customized Products: When responding to offers with specific reliability constraints, the objectives must align with the offered constraints. Here, we verify the objectives based on the provided dedicated RAMS documents from the supplier.
Two ways to estimate reliability
The estimation of reliability, through the notion of failure rate, or MTBF, is done with trials if no reliability data is available or deducted from the existing reliability data.
- Predictive Reliability for Complex Integrations: In large integrations with numerous subsystems, relying on trials becomes impractical due to complexity and the cost it would require. Instead, we utilize the components’ own trial data and/or databases that provide failure rate information for some components. The global failure rate, or MTBF, is then deduced with RAMS calculation tools such as FMCA (Failure Modes, Effects, and Criticality Analysis), reliability block diagrams, or fault tree analyses. All these calculation methods are discussed in the next sections.
- Experimental reliability using trials: Experimental reliability trials involve testing components or systems to assess their performance. The accuracy of the results increases with the scope of the trials, measured in terms of both duration and the number of units tested. These trials are conducted when a component lacks comparable data from past experiences or when a system exhibits a high level of cohesion among its components, making them statistically non-independent. Achieving independence among the components of a system is necessary for making accurate predictions. For example, thermal engines, although very complex, often exhibit a high degree of interdependence, as is common in mechanical systems. For instance, if overheating occurs due to a faulty coolant pump, it could lead to the failure of many parts. Similarly, undesired vibrations in moving parts could cause wear and tear in various components. Therefore, despite their high cost, trials are often the only viable option in such scenarios.
Failure Modes and the Influence of Conditions of Use
Understanding the modes of failures becomes imperative, distinguishing between intrinsic and extrinsic factors:
- Intrinsic Failures: These are intricately tied to the product itself. A classic example involves a faulty water pump causing engine overheating, ultimately leading to a head gasket failure.
- Extrinsic Failures: The influence of conditions of use cannot be overstated. Mission profiles come into play, encompassing the time spent in each life phase, environmental considerations (temperature, humidity, vibrations), and other usage-related aspects.